
Yes, you read it right. And not only in chemistry, but all models are wrong in science. And probably not only in science, but any geographical, economic, or business model too.
You might think now, “What is this guy saying?” Give me just some minutes to explain what I have to tell you here to all of you.

All right, first of all, what is a model? People usually call models the building blocks of science. The model is the basic element of the scientific method. In science we study and predict the behavior of many kind of systems, and we use models to simplify, substitute or stand-in for this properties and behaviors of systems.
But do not limit the concept of a model only for science or chemistry: You can find models everywhere (we get carried by them while performing experiments in the lab) and the following examples will make the understanding of the concept of model very easy to anyone. These are examples of “everyday models”.
- A recipe of a delicious dish is a model of the actual process of cooking the dish.
- A photography album of a trip is model of the trip.
- The news report about a football match is a model of the football game itself.
- The promises that a political candidate make in his campaign is a model of its performance if he is elected (or at least it is supposed to be)
You can see that, out of those, all models are wrong, but some are useful.
All models are wrong, but some are useful
Another example, closer to science: Statistical studies about what kind of shoes a population prefers are a model of their real preferences. I suppose that at this point you probably started to get what I was referring to with my first sentences.
Now I want to quote George E. P. Box, who was an English statistician who worked amongst other things, on quality control and time-series analysis:
“Essentially, all models are wrong, but some are useful”
The meaning of this statement makes up the cornerstone of the idea I want to transmit with this article, and I will discuss it in two parts:
“Essentially, all models are wrong… means that any model will be wrong because it is by definition a simplification of reality. Of course one model can be “more wrong” than another. Generally in the most “strict” sciences, like mathematics or logic, models approximate more to reality. For example, physicists often ignore things like gravitational effects on very little objects, or friction. Other models ignore a lot of things, like for example a demographic study about a large population. But in general, models cannot totally recreate all the physical reality.
…but some are useful”. Of course they are! We use them all the time, and without them there is no chemistry, there is no science, there is no any kind of study! Simple models and approximations help people explain things, predict behaviors and understand properties, from very little changes in tiny systems to the whole universe.
I like to use my favorite “useful wrong model” to exemplify this: A map.
When someone says that a map is wrong, he is just trying to say that a street is mislabeled, or a building does not appear or is not placed where it should. That guy would never expect the map to perfectly recreate reality, because doing such an impossible thing is not the goal of a map. The guy will get only pissed off if the model cannot respond to the questions that he needs answered. Unless you have an outdated map, it will not be wrong for its purpose.
Nonetheless, a model will never provide a hundred percent accurate explanations or predictions that you can apply in any case. Randomness exists. Uncertainty and errors exist. Finding a model that has not any of these components will mean that you do not have a model anymore, you just have a fact.
In theory, if you have perfect data, great computing tools you could create a model that can predict properties, behaviours or events perfectly. But even in this case, you will have an extremely complex model that the computational power needed to take advantage of will make it non-viable.
Of course, you can find in any science very complex models that you can actually apply, and obtain results. And I promise that you can obtain very good ones, with less randomness, error and uncertainty than simpler models, which you can call more inaccurate, “more wrong” models. Does this make the simpler models obsolete? Of course it does not. If a model is useful to some extent, you can continue using it.
When do you reject a model? Only in the case that you find a new model that explains things better than the older one and it is incompatible with it. It is said that the model is outdated.
Now the time of getting into chemistry has come! What it could not be done otherwise, we will apply now all what we just have learnt to our field of science.
I want to discuss two models, and I will leave my favorite example to the end of the article, so continue reading, you will not be disappointed and relize that indeed all models are wrong.
The Crystal Field Theory as a Model in Chemistry
The first model I will discuss is the Crystal Field Theory. If you have taken a few courses on Inorganic Chemistry, you will probably know this model very well. For those who do not know it, Crystal Field Theory (CFT) is an electrostatic model that describes the loss of degeneracies of the d orbitals of the central metal ion of a coordination compound.
If you have an isolated metal ion, like, let’s say, Cu2+, all the five d orbitals have the same energy. But when ligands (certain molecules or ions with partial or net negative charge) are placed around the metal, due to electrostatic interactions, these orbitals do not have the same energy anymore, and they split in different energy levels. We are going to stick with the octahedral splitting (when 6 ligands bind to the metal forming an octahedron):
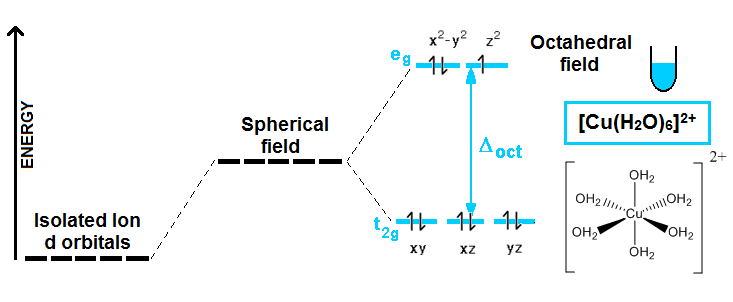
This example shows what happens when a Cu2+ isolated ion, (in reality, this can be any salt where the copper ions are not coordinated with any ligand) is added to a beaker containing water. In principle, the d orbitals had the same energy, but when 6 water molecules are located around the central copper ions, due to electrostatic interactions, they split to give rise to two different energy levels. Experimentally, you can observe a blue color in the solution like the one represented in the picture. Why does that happen and why an anhydrous copper salt shows no color? Well, this is definitely an experimental fact that can be explained with this wrong (we will see why CFT is wrong in a minute) model! There is a d orbital that is half-empty on the upper energy level, and one electron from the lower can “jump” from one to another, if the appropriated light is absorbed.
∆oct equals the energy difference between the two energy levels. And when light of this energy is absorbed, one electron is promoted or excited to the higher level. Well, this kind of light happens to be in the visible range of the electromagnetic radiation spectrum; specifically it is red-orange light. So, the compound will show the complementary color of the absorbed light, in effect, cyan blue color.
We have just seen that CFT can explain and even predict in some cases, properties like the color of coordination compounds (amongst other properties, like its structure, or magnetic properties), but this is a completely wrong model!
Why? Because it only takes into account electrostatic interactions between the metal ion and the ligands, and this definitely does not happen! There is a strong covalent bonding character in coordination complexes and without taking it into account, many things cannot be explained (e.g. the spectrochemical series), so it is a completely wrong model, but that is useful to easily explain and predict certain properties. Again, we see how all models are wrong, to some extent.
Advanced Models in Chemistry: Molecular Orbitals Theory
Molecular Orbitals Theory can, in contrast, predict and explain all of the properties and behaviours that CFT can do, and many much more, and moreover, not only qualitatively, but also quantitatively. But MOT is way more complicated, and its application to a bit complex systems requires the use of large calculations using powerful computers. There is another model, the Ligand Field Theory, which is fairly “less wrong” than CFT, since it takes into account the basis of CFT and also the basis of molecular orbital theory, and is the most widely used if you want to find a good compromise between usefulness and accuracy.
To finish this article, I want to discuss my favorite example of a widely used model, which is the concept of hybridization. Many undergraduate chemistry students talk about hybrid atoms in a molecule as if hybridization was an intrinsic property of the atoms.
Let’s clear something up: Atoms in a molecule are not hybridized. Hybridization makes up just a model that we employ to justify or explain molecular structures and geometries. It is just another simple model that we use to make our lives easier.
Of course, when studying large organic molecules reactions, we cannot just start applying the complex molecular orbital theory to every atom in our compounds; we would end up crazy (if we ever end up anything), so we take advantage of simpler models and just move electrons around in our Lewis structures to explain reaction mechanisms.
I want to illustrate the non-existent need of using specific hybridizations to explain single, double and triple bonds between organic molecules carbon atoms. This is very funny, believe me.
What is usually taught is that when a carbon forms only single bonds it is sp3 hybridized. When it forms a double bond, it is sp2 hybridized, and the remaining p orbital forms the π bond. And when it forms a triple bond, it is sp hybridized, and the two remaining p orbitals, create the two π bonds. Well, Pauling explained that electron distribution in alkenes or alkynes can easily be explained using only sp3 orbitals: two sp3 orbitals overlap in something between a σ and a π bonding (Fig. 1) and we end up with exactly the same electronic distribution than when we use the classical one.
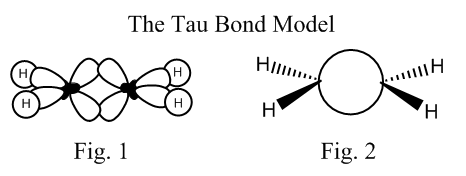
This last model can be represented using something like “bridge” lanes (Fig. 2), and the resulting kind of bond is called “Tau bond”, and even though is not a very useful model (sometimes it can be used to explain stereochemistry of organic reactions), it is an absolutely legitimate and very nice and model in the sense that can be used to illustrate the main purpose of my writing: All models are wrong. All models must be treated like what they are, simplifications and approximations that have to be used always taking into account its limitations, and never ever be confused with facts.
If you are eager to learn chemistry, I have put together several reviews on books for learning chemistry, that can be all found here. For example, check here the best organic chemistry textbooks for you. But always keep in mind, models are just models!
Furthermore, if you happen to be preparing the AP chemistry final, make sure to go and check out the best AP chemistry review books out there!
I hope you have enjoyed the reading, and now it’s your turn! Share your thoughts and opinions on the comments. Your participation make Chemistry Hall grow and encourage me to continue writing. Do not forget to subscribe to our news feed and feel free to continue exploring the website. In case you are a hobby chemist, don’t wait to check our guide to set up a home chemistry lab!
Many good points. Le Chatelier and Markownikoff are two examples that come to mind of methods that work but whose “story” has little basis in fact. The idea of the reagents trying to restore an equilibrium position gives the right answer but conjures up the picture of some kind of molecular debating chamber where decisions to favour the endothermic reaction are made so that the temperature can be reduced to re-establish the status quo.
Thanks for promoting discussion. It is good to re-examine how we as teachers see the chemistry so that we can minimise the misconceptions we set up for students.
I agree. As a chemistry undergrad, I am aware that several of the models we use to understand fundamental chemistry are technically incorrect. But they have persisted because they are easier for someone at our knowledge level to understand/internalize.
I can’t really think of any clear way to avoid that, considering that people struggle enough in class as it is.
Unfortunately, some scientists who work in rigorous areas in the fields of mathematics and physics, for example, seem to occasionally take umbrage with the qualitative nature of many of the models used in Chemistry. I know of one physicist/engineer who refers to Chemistry as “the class where you learn things that can’t possibly be true”, or “where you go to unlearn what you just worked hard to learn.”
In some ways, these people have a point – for instance, we teach students the octet rule, then explain that it doesn’t provide a framework the magnetic behavior of diatomic oxygen. Or we teach broad features of orbital structure and filling (Aufbau principle and such), then proceed to explain to students that the rules/guidelines we just gave them don’t work for all elements – there are a whole list of them that have a different electron configurations than are predicted by the Aufbau and pauli exclusion principles.
Personally, I do not find myself bothered by such examples – I look at these models (“incorrect” though they might be) as incrementally (and sometimes, exponentially) more complex, and more complex models allow for a greater understanding of nuance and variation. The learning of a simple model provides a cognitive space for a student, which can then be refined and enhanced in developing understanding of more complex behaviors. This is normal, this is learning, and to develop deeper understanding successfully requires thought and careful consideration.
Personally I like very much the following sentence by Dewar:
“The only criterion of a model is usefulness, not its “truth””
M. J. S. Dewar, JACS 106 (1984) 669